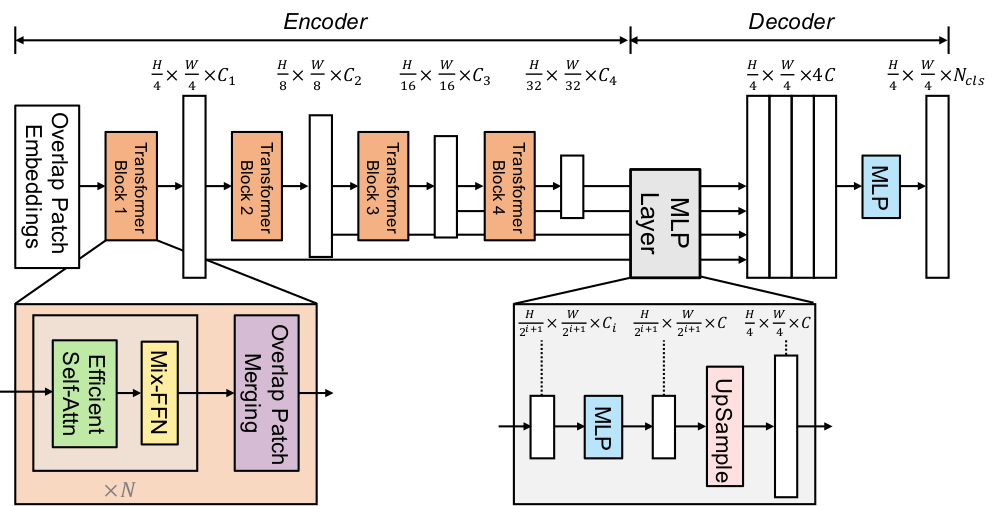
SegFormer

openi_paper/pytorch-image-models: PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, EfficientNetV2, NFNet, Vision Transformer, MixNet, MobileNet-V3/V2, RegNet, DPN, CSPNet, and more - pytorch-image-models - OpenI - 启

Sébastien BUBECK, Princeton University, New Jersey, PU, Department of Operations Research and Financial Engineering

We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
PDF) Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives

Recent Developments and Views on Computer Vision x Transformer
GitHub - leondgarse/keras_cv_attention_models: Keras beit,caformer,CMT,CoAtNet,convnext,davit,dino,efficientdet,edgenext,efficientformer,efficientnet,eva,fasternet,fastervit,fastvit,flexivit,gcvit,ghostnet,gpvit,hornet,hiera,iformer,inceptionnext,lcnet

Ananya Kumar's research works Stanford University, CA (SU) and other places

ViTMatte: Boosting image matting with pre-trained plain vision

timm - Python Package Health Analysis

The freeze out distribution, f f ree (x, p), in the Rest Frame of the

The freeze-out distribution, f f ree (x, p), in the rest frame of the
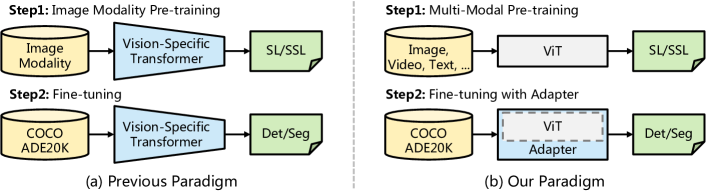
2205.08534] Vision Transformer Adapter for Dense Predictions
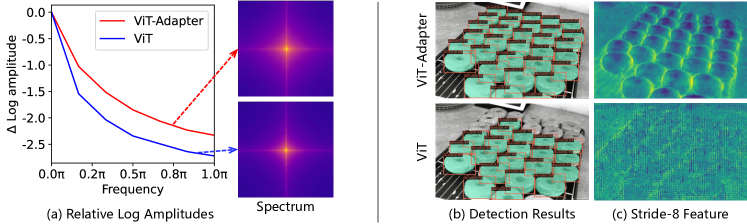
2205.08534] Vision Transformer Adapter for Dense Predictions